经过多次尝试构建本地文档问答、构建思维链解决复杂场景问答、自定义构建Agent解决特定场景问答后,我开始察觉到其所存在的限制。
上下文长度的局限性
通信带宽的有限性限制了上下文容量。这限制了历史信息、详细说明、API调用上下文和响应的包含。对于系统设计来说,必须应对这种限制。长期的上下文窗口有助于自我反思机制和从过去的错误中学习。虽然向量存储和检索可以提供对更大知识库的访问,但它们的表示能力不如充分关注那么强大。
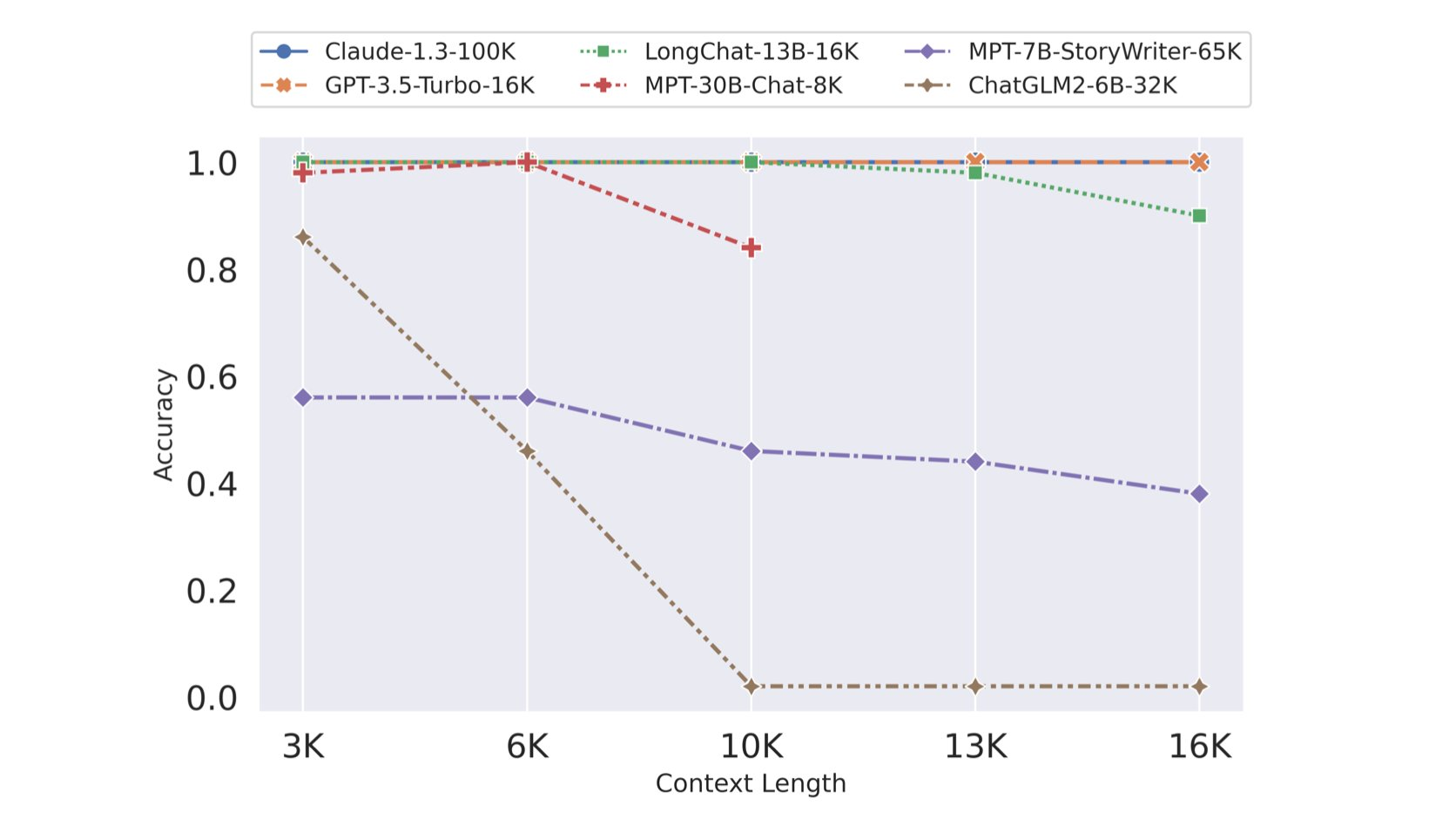
开源LLM们在加大上下文容量的最新进展
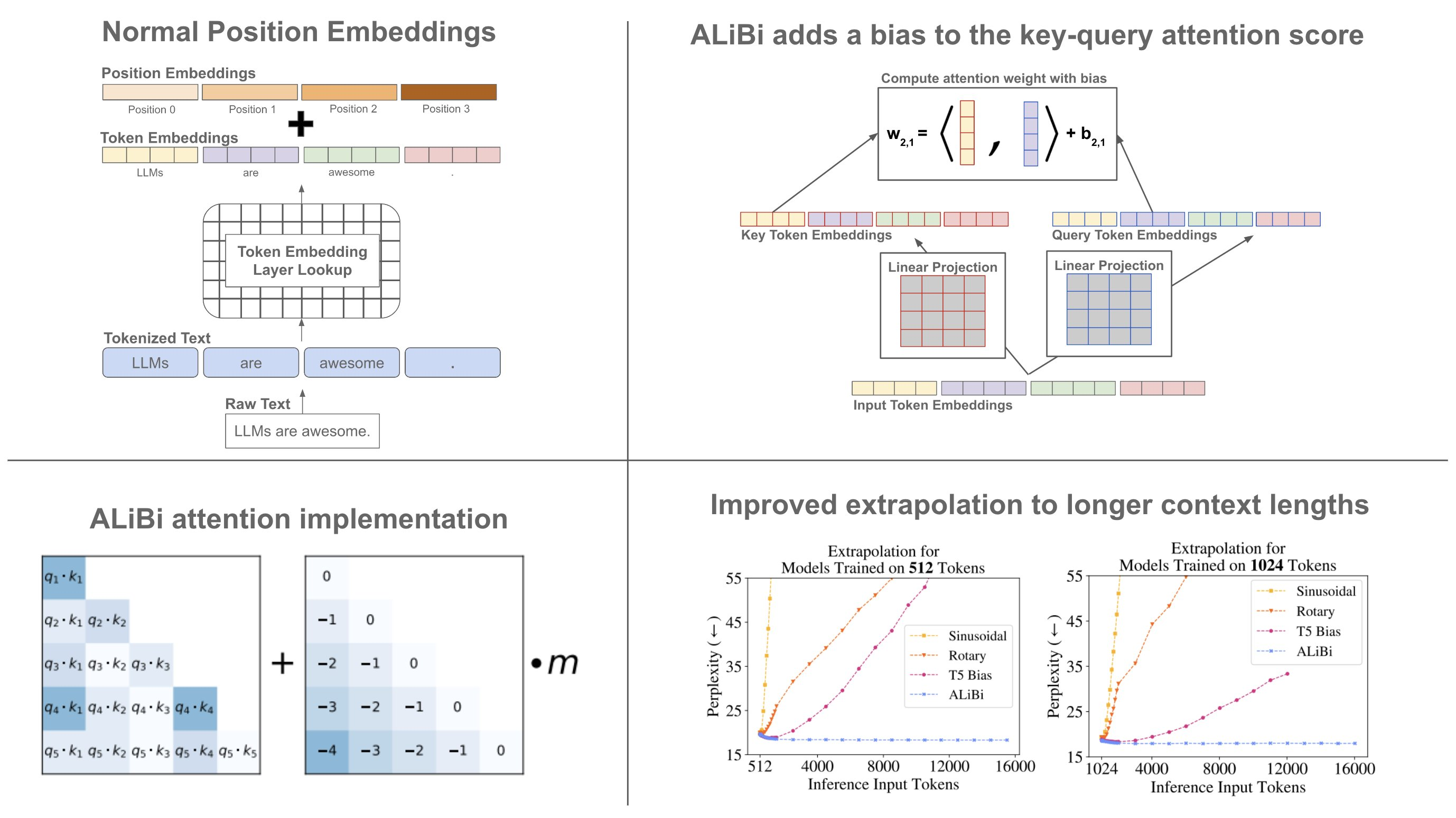
长下文长度背后的技术-ALiBi
- position embeddings
长期规划和任务分解的挑战
长期规划和有效探索解决方案空间仍然尚存在挑战。当遇到意外错误时,调整计划对法学硕士来说是困难的。这使得它们与能够从试错中学习的人相比缺乏稳定性。
自然语言接口的可靠性
当前的代理系统是依赖自然语言作为LLM与外部组件(例如内存记忆和工具)之间的接口。然而,模型输出的可靠性存在问题。因此,大部分Agent的演示代码都会专注于解析模型输出。由于LLM模型可能存在格式错误,偶尔会表现出叛逆行为(例如拒绝遵循指示),因此其输出的可靠性值得质疑。