挖掘导演最爱用的演员 关联规则-FPGrowph
概要
Aprior
和Apriori比较
FP的全称是Frequent Pattern,在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快整个挖掘过程。
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了频繁出现的数据集,那么对于超市,我们可以优化产品的位置摆放,对于电商,我们可以优化商品所在的仓库位置,达到节约成本,增加经济效益的目的。
- 通过构造FP树和项头表来存频繁项集
- 整个过程只遍历数据2次
关键概念
置信度
条件概率,置信度(A->B) 在A出现的条件下B发生的概率
支持度
某个组合出现的概率(出现的次数/总的次数)
提升度
提升度(A->B) = 置信度(A->B)/支持度(B) = P(B|A) /p(B) = P(AB)/(P(A)*P(B))
A的出现对B发生的概率有多大的提升 (B发生的所有条件里 A发生导致B发生 所占的比例)
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
+------------+----+
| items|freq|
+------------+----+
| [黄渤]| 6|
| [徐峥]| 6|
|[徐峥, 黄渤]| 6|
+------------+----+
+----------+----------+----------+------------------+
|antecedent|consequent|confidence| lift|
+----------+----------+----------+------------------+
| [徐峥]| [黄渤]| 1.0|1.6666666666666667|
| [黄渤]| [徐峥]| 1.0|1.6666666666666667|
+----------+----------+----------+------------------+
导演宁浩的电影中出现频率最高的演员是 徐峥, 黄渤
导演最爱用的演员
val dataset = spark.createDataset(Seq(
"郭涛,刘桦,连晋,黄渤,徐峥,优恵,罗兰,王迅",
"徐峥,黄渤,余男,多布杰,王双宝,巴多,杨新鸣,郭虹",
"黄渤,沈腾,汤姆·派福瑞,马修·莫里森,徐峥,于和伟,雷佳音,刘桦",
"黄渤,戎祥,九孔,徐峥,王双宝,巴多,董立范,高捷",
"黄渤,徐峥,袁泉,周冬雨,陶慧,岳小军,沈腾,张俪",
"雷佳音,陶虹,程媛媛,山崎敬一,郭涛,范伟,孙淳,刘桦",
"徐峥,陈思诚,邓超,俞白眉,闫非,彭大魔,黄渤,王宝强,刘昊然,佟丽娅,吴京,张译,雷佳音",
"张子贤,李嘉宇,李世成,孙麒鹏,王晶晶",
"达瓦,毕力格,戈利班",
"葛优,刘德华")
).map(t => t.split(",")).toDF("items")
val fpgrowth = new FPGrowth().setItemsCol("items").setMinSupport(0.4).setMinConfidence(0.6)
val model = fpgrowth.fit(dataset)
// 展示频繁项集
model.freqItemsets.show()
// 展示关联关系
model.associationRules.show()
算法步骤
- 整理数据,获得事务数据集
- 计算每项的支持度,形成项头表
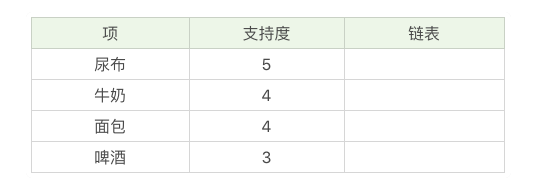
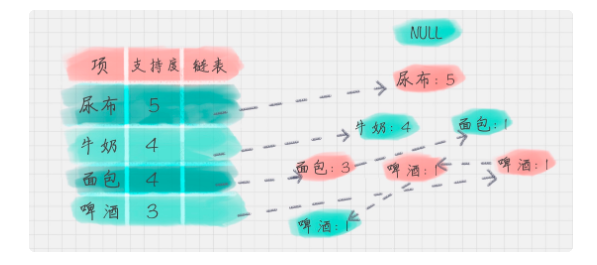
- 每个事务内按照 支持度对每项进行筛选、排序,更新项头表的链接和计算
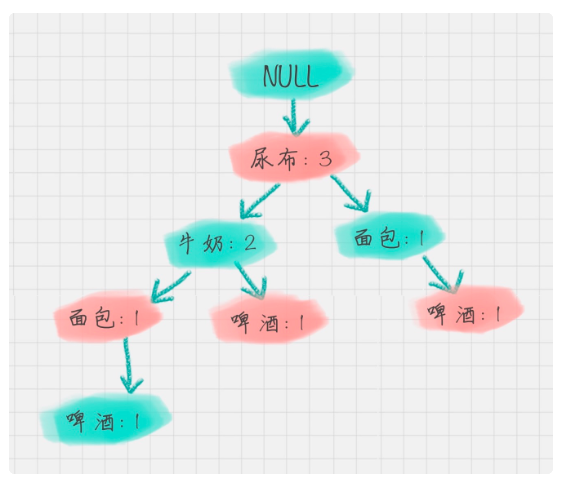
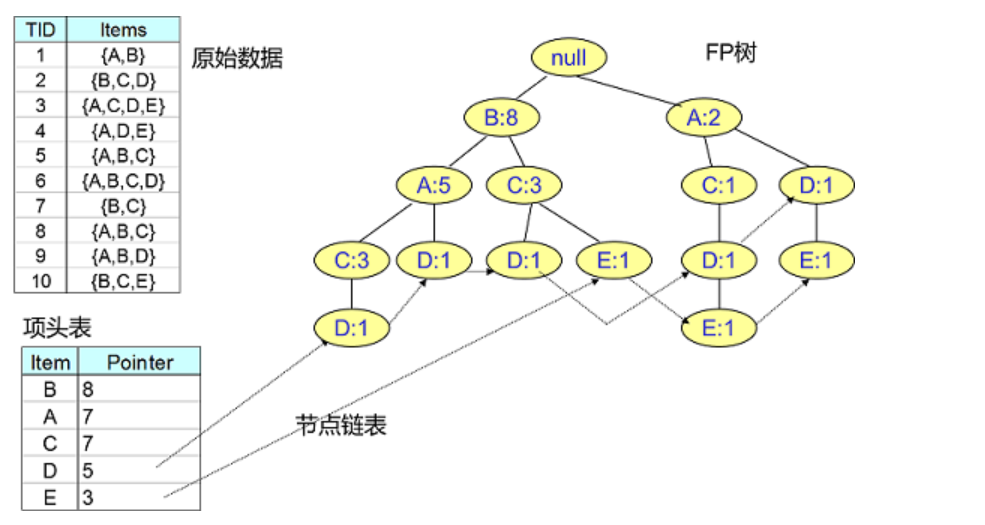
- 构建fp树
-
4.1 扫描事务数据库D一次。收集频繁项的集合F和它们的支持度。对F按支持度降序排序,结果为频繁项表L。
-
4.2 创建FP-树的根结点,以“null”标记它。
对于D 中每个事务Trans,
执行:选择 Trans 中的频繁项,并按L中的次序排序。设排序后的频繁项表为[p | P],其中,p 是第一个元素,而P 是剩余元素的表。调用insert_tree([p | P], T)。该过程执行情况如下。如果T有子女N使得N.item-name = p.item-name,则N 的计数增加1;否则创建一个新结点N将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name的结点。如果P非空,递归地调用insert_tree(P, N)。
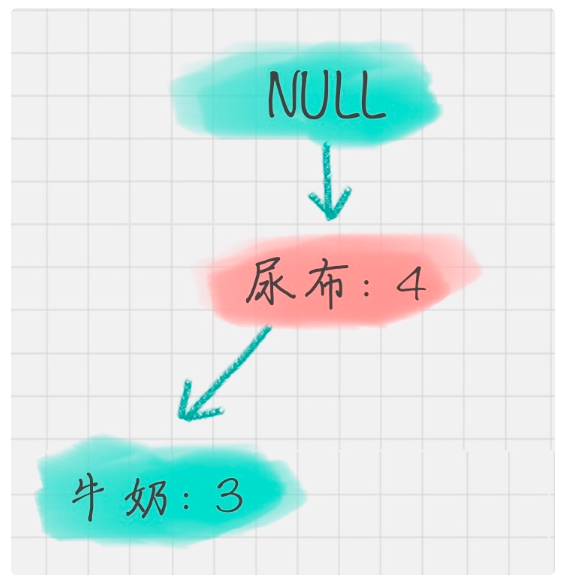
- 挖掘每项的频繁项集
通过调用FP_growth(FP_tree, null)实现。该过程实现如下:
FP_growth(Tree, α)
(1) if Tree 含单个路径P then
- for 路径 P 中结点的每个组合(记作β)
- 产生模式β ∪ α,其支持度support = β中结点的最小支持度;
(4) else for each ai在Tree的头部(按照支持度由低到高顺序进行扫描) {
- 产生一个模式β = ai ∪ α,其支持度support = ai .support;
- 构造β的条件模式基,然后构造β的条件FP-树Treeβ;
- if Treeβ ≠ ∅ then
- 调用 FP_growth (Treeβ, β);}
end
- 关联规则的评估
每个事务可以表示为 每个锚段一个月发生的缺陷种类
Spark Mllib FPGrowth 源码
FPGrowth源码包括:FPGrowth、FPTree两部分。
其中FPGrowth中包括:run方法、genFreqItems方法(频繁项)、genFreqItemsets方法(频繁项集)、genCondTransactions方法(条件事务)、FPGrowthModel类;
FPGrowthModel中包含:generateAssociationRules方法(生成关联规则);
FPTree中包括:add方法(频繁树添加)、merge方法(频繁数合并)、project方法(根据后缀获取子树)、getTransactions方法(返回所谓事务)、extract方法(挖掘所有满足后缀和最小支持度的规则)。
参考博客
https://www.cnblogs.com/zhengxingpeng/p/6679280.html
https://www.cnblogs.com/pinard/p/6293298.html